前言
SDD是近期备受关注的一个概念。随着AI极大提升了代码生成的速度,一度流行的“vibe coding”逐渐暴露出问题:开发者用“帮我加个分享功能”这类模糊提示词让AI写代码,结果往往充满不确定性,返工成本居高不下。AI虽然难以猜透人的真实意图,却能精准执行明确的规范。而LLM与Coding Agent的发展,恰好为SDD从学术概念走向工程实践提供了有力支撑。如今,SDD已成为AI编程领域绕不开的话题。
目前在编程领域,有非常多优秀的工具在支撑SDD的工作流程,比如Spec Kit、OpenSpec、Kiro等等。其中OpenSpec以其开源、基于变更、轻量、通用等诸多优势,成为众多开发者喜爱的SDD实践工具。本文将深入拆解OpenSpec的各项功能特性,帮助大家理解:当我们使用OpenSpec进行SDD进行实践时,我们每一步在做什么,以及为什么要这么做。
本文默认读者已经具备SDD的基本概念和知识,不对这部分概念展开讨论。
使用OpenSpec,你应该知道的事情
OpenSpec的安装可以参考官网。
本文的所有指令和功能基于目前最新版本的OpenSpec(1.3.0)
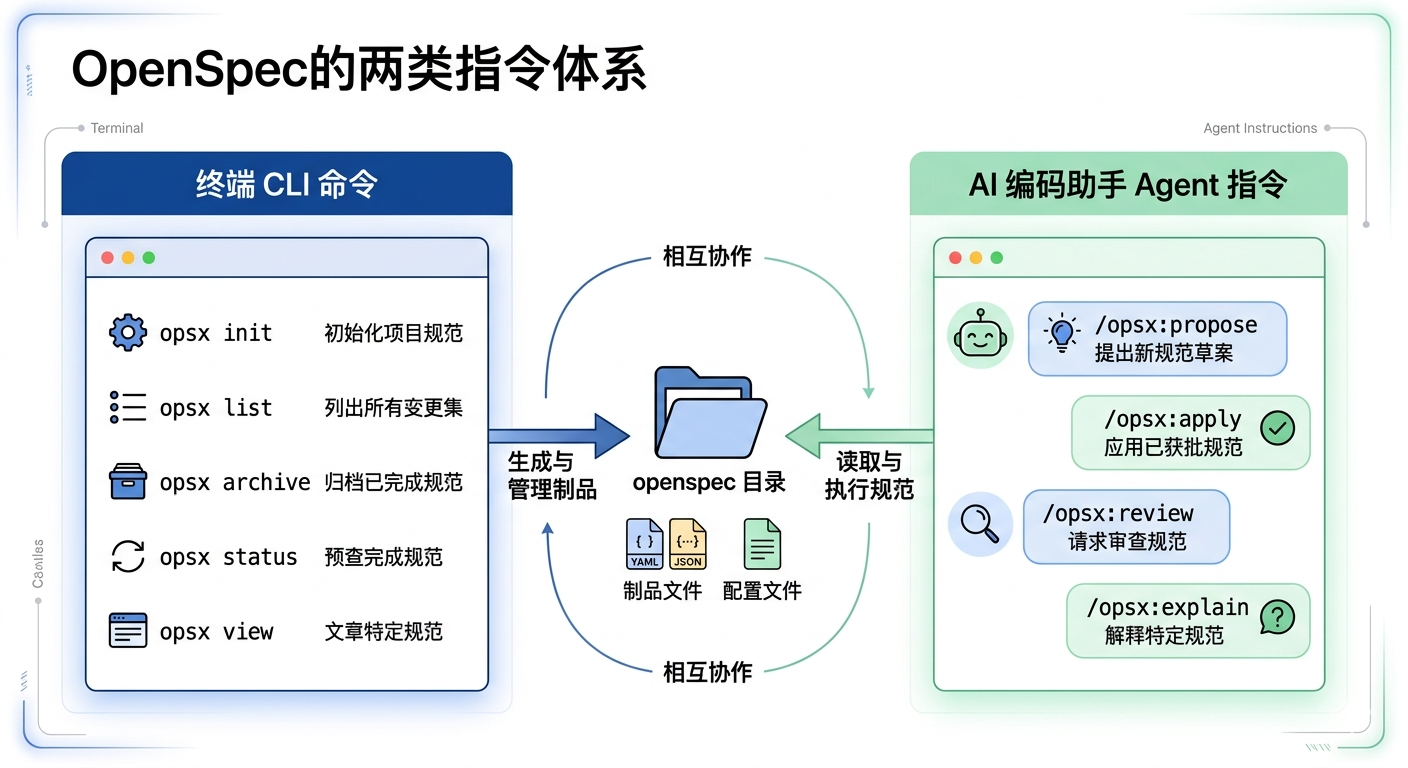
OpenSpec包含两类指令功能,第一类是cli命令,第二类是开发过程的Agent指令。
Cli命令
日常开发(高频)
| 命令 | 场景 |
|---|---|
| init | 新项目首次接入 OpenSpec |
| update | 升级 CLI 包后,刷新 AI 工具配置 |
| list | 查看当前有哪些活跃变更或规格 |
| show | 查看某个变更或规格的详细内容 |
| status | 查看变更的 artifact 完成进度 |
| archive | 终端中直接归档已完成的变更 |
| validate | 检查变更或规格的结构是否合规 |
工作流调试(中频)
| 命令 | 场景 |
|---|---|
| instructions | 调试 agent 行为,查看某个 artifact 的生成指令 |
| templates | 确认 schema 模板文件的实际路径 |
| schemas | 列出所有可用 schema 及其来源 |
| view | 交互式仪表盘,总览项目状态 |
自定义 Schema(低频)
| 命令 | 场景 |
|---|---|
| schema init | 从零创建自定义工作流 |
| schema fork | 基于内置 schema 定制自己的版本 |
| schema validate | 验证自定义 schema 结构是否正确 |
| schema which | 排查 schema 解析优先级问题 |
配置管理(低频)
| 命令 | 场景 |
|---|---|
| config profile | 切换 core/custom 工作流模式 |
| config list | 查看当前所有配置项 |
| config get/set | 读取或修改单个配置值 |
| config edit | 用编辑器直接编辑配置文件 |
| config path | 找到配置文件位置 |
| config unset | 删除某个自定义配置项 |
| config reset | 恢复默认配置 |
一次性的
| 命令 | 场景 |
|---|---|
| completion | 安装 shell 自动补全 |
| feedback | 提交反馈,自动创建 GitHub issue |
第二类是开发过程使用的Agent指令:
| 命令 | 用途 |
|---|---|
| /opsx:propose | 一步创建变更并生成所有规划制品 |
| /opsx:explore | 探索想法、调研问题,不创建制品 |
| /opsx:apply | 执行 tasks.md 中的实现任务 |
| /opsx:archive | 归档已完成的变更,合并 delta specs |
| /opsx:new | 仅创建变更脚手架,等待后续指令 |
| /opsx:continue | 按依赖顺序逐个创建 artifact |
| /opsx:ff | 一次性创建所有规划制品 |
| /opsx:verify | 校验实现与规格的一致性 |
| /opsx:sync | 将 delta specs 合并到主规格 |
| /opsx:bulk-archive | 批量归档多个变更,自动处理冲突 |
| /opsx:onboard | 引导式教程,用真实代码走一遍完整流程 |
还有三个已废弃的指令不做讨论:/openspec:proposal、/openspec:apply、/openspec:archive
基础功能
快速流程
官方提供的快速流程只有三步:
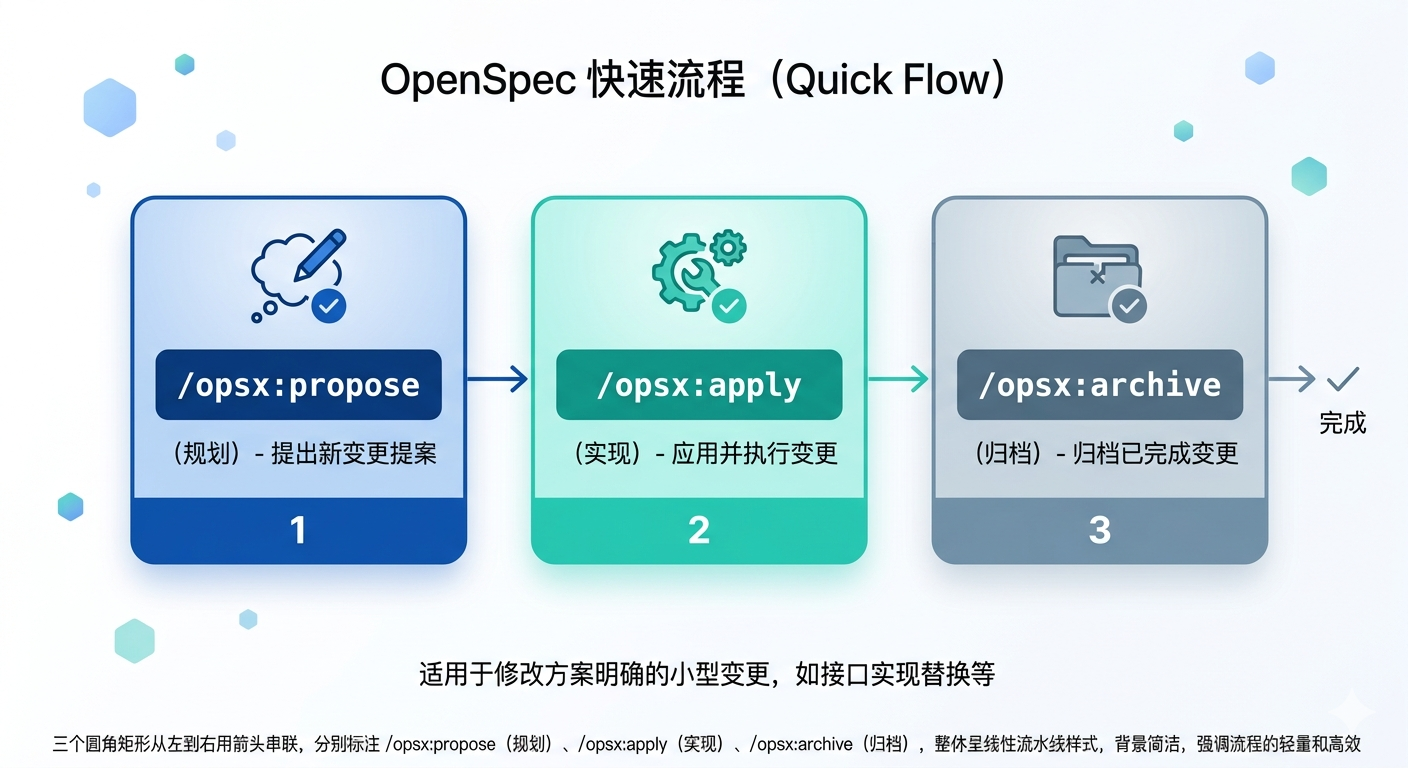
/opsx:propose ──► /opsx:apply ──► /opsx:archive
这个流程非常适合一个修改方案很明确的小变更,比如:修改锁接口的实现类,从内存锁改为分布式锁,这类变更技术方案完全是确定的,只是将一个接口的实现类实用另一种方案重新实现一次,并替换实现类而已,无需过多的思考和探索。
扩展流程
扩展流程是官方提供的一个更详细的流程,它的本质是把/opsx:propose的环节,拆分为变更创建 -> 制品编写的过程,其中制品编写一般分四个制品:提案,规范,设计,任务。
官方给出的标准扩展流程为:
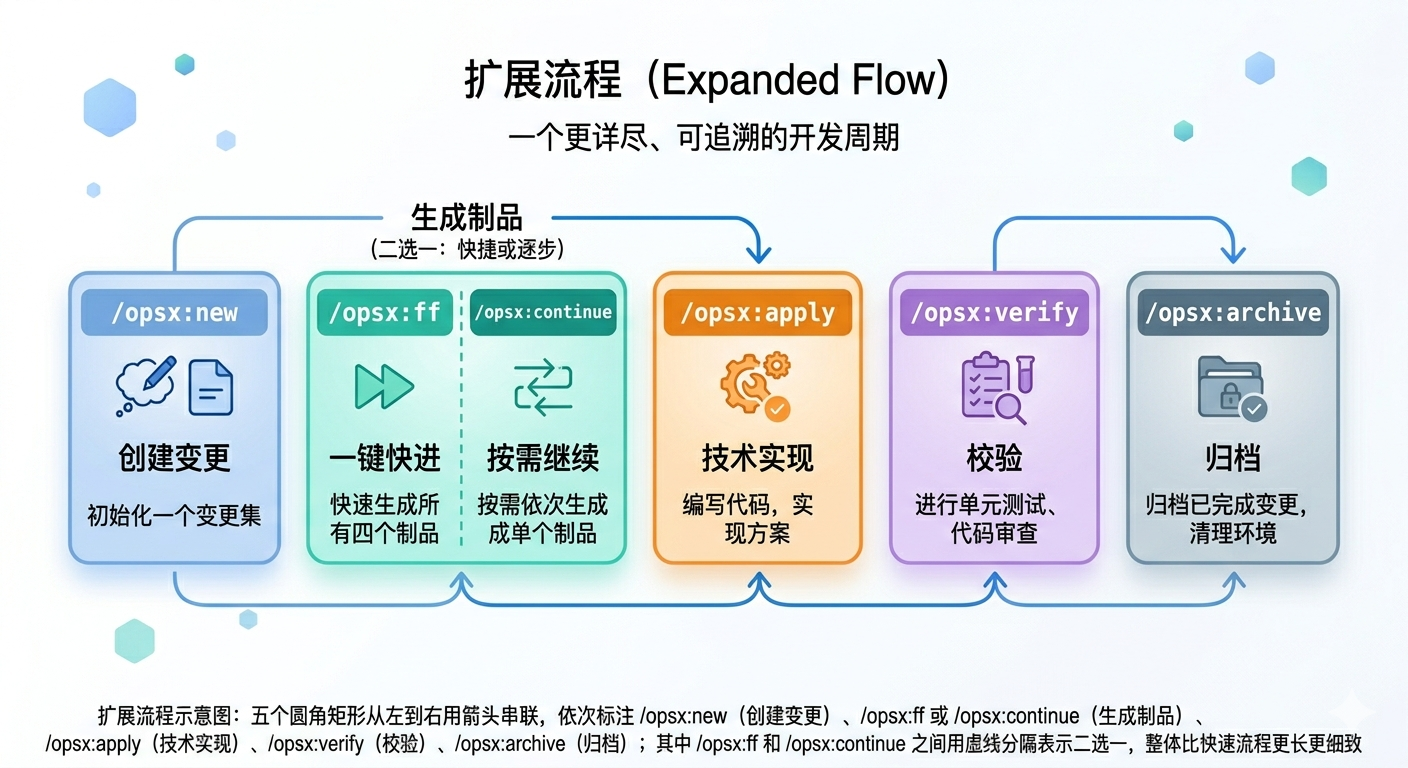
/opsx:new ──► /opsx:ff or /opsx:continue ──► /opsx:apply ──► /opsx:verify ──► /opsx:archive
说明:这里
/opsx:ff含义是Fast Forward(快进),表示的是一次性完成所有制品,在早期的版本相当于/opsx:continue * 4快速流程里的
/opsx:propose相当于/opsx:new + /opsx:ff,所谓的快速流程本质上只是通过一个指令同时完成多个步骤而已。 (值得说明的是在目前的版本下,/opsx:ff已经约等于/opsx:propose了)
概念理解
了解OpenSpec的基本流程之后,现在我们来真正深入的了解,它每一步到底在做什么,为什么要这么做。
首先我们知道,OpenSpec的核心是变更(change),也就是每一次新的变更都是一个小的SDD过程,因此会包含SDD的所有环节。
在前面的两个标准流程中,其实可以分为三个环节:
- 文档编写(从
/opsx:new到/opsx:apply之前) - 技术实现:
/opsx:apply - 收尾工作:
/opsx:verify到/opsx:archive
这里并不是按照SDD流程来划分的环节的,而是将所有的文档编写统一到一个环节,如果按照SDD流程拆分应该是如下:
- 需求沟通:
/opsx:new - prd文档:
/opsx:continue* 2 - 制定计划:
/opsx:continue* 2 - 技术实现:
/opsx:apply - 收尾工作:
/opsx:verify到/opsx:archive(扩展步骤)
归档
在OpenSpec中,虽然遵循SDD的开发流程,但是也通过/opsx:propose和/opsx:ff的方式来简化流程,提高需求落地的效率,这些相对好理解,但是最后的收尾工作环节,是为了什么?
/opsx:verify的作用是检查本次变更的所有工作是否按照规范完成,所有任务是否完成,并不是必选的,只有较大的复杂变更,才有必要在技术实现完成后进行一次验证,所以OpenSpec并没有将这个环节放在技术实现阶段。
我们重点看归档指令:/opsx:archive
为什么要对变更归档?归档的过程做了什么?
规范层次
在理解为什么要对变更归档前,我们要先了解OpenSpec中定义的规范分层结构:
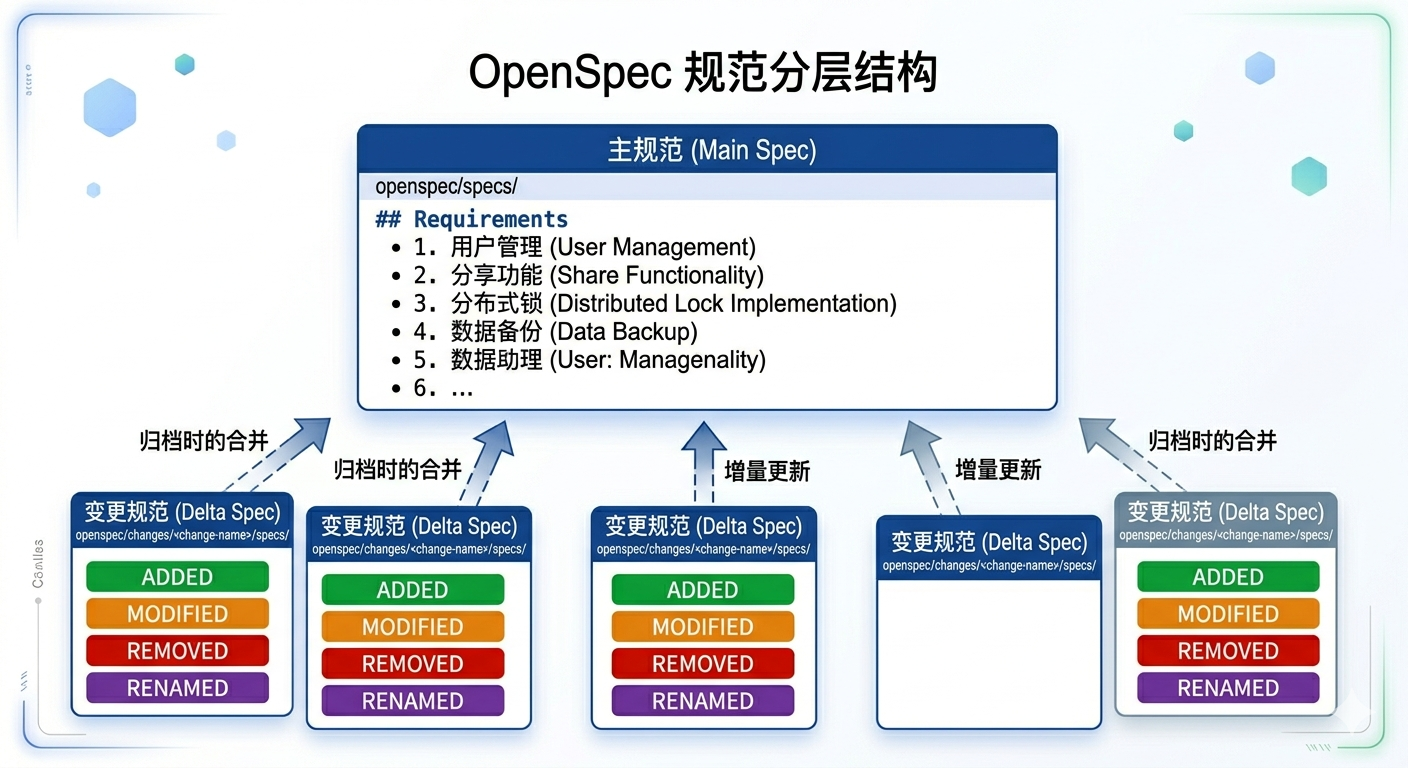
- 主规范(Main Spec): 主规格是系统当前行为的完整描述,存放在 openspec/specs/{capability}/spec.md。它只有一个
## Requirements部分,包含该能力下所有需求的完整定义; - 变更规范(Delta Spec):变更规格是一次变更对主规格的增量修改,存放在 openspec/changes/{change-name}/specs/{capability}/spec.md。它不重复已有内容,只描述”这次要改什么”,用四个增量操作来表达(ADDED/MODIFIED/REMOVED/RENAMED);
我们在每一次新变更的开发中,实际上产生的都是变更规范,变更的规范相比于主规范是有可能存在差异的,而且变更规范也不会全局考虑所有功能,只是一个变更历史。
主规范是整个项目非常重要的资产,按照要求,它应该完整的描述了整个项目当前的情况,包含各个模块的功能,需求和系统行为定义。非常有助于未来新的维护者或者AI加入时理解系统。
归档过程
现在我们可以回答为什么要归档了:为了保持主规范能够准确描述整个项目当前的所有需求和能力定义。
那归档到底做了什么?
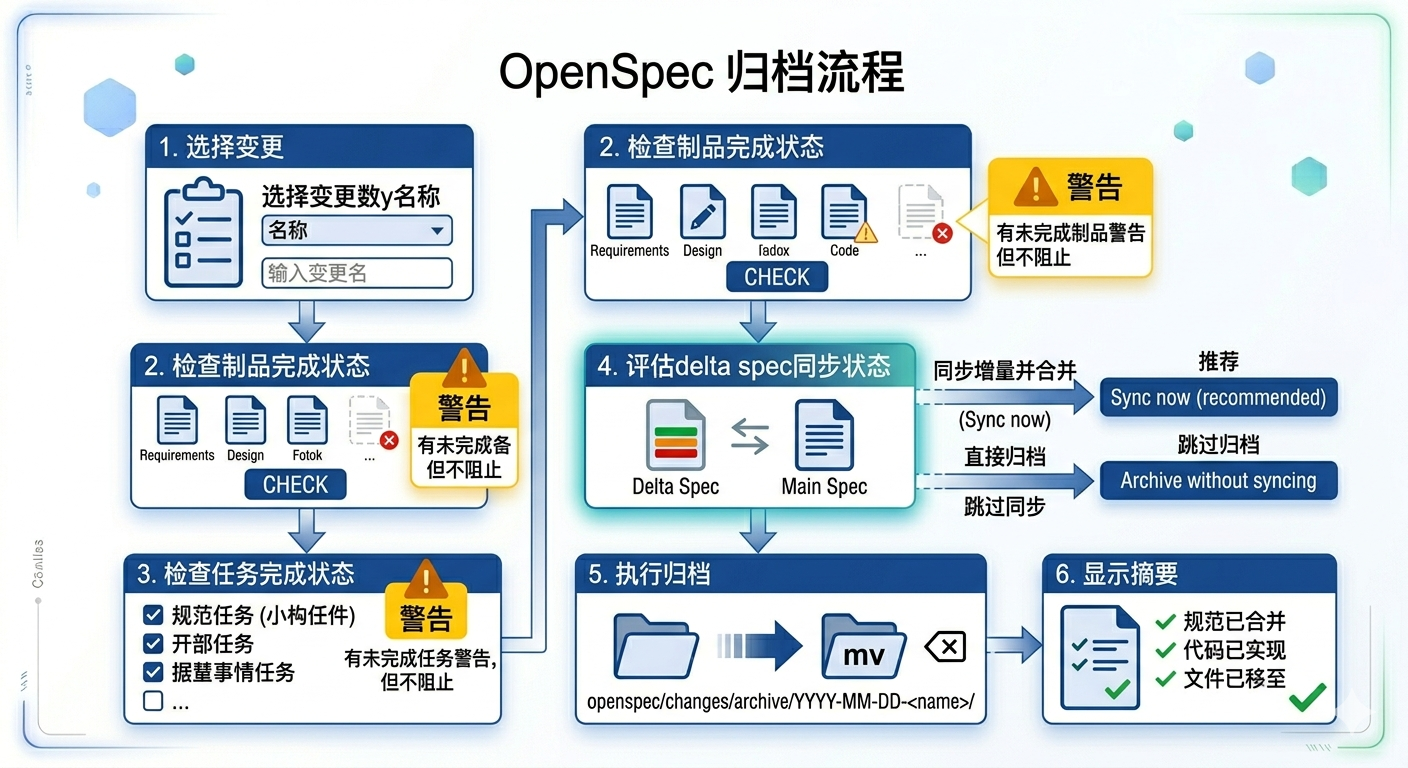
事实上当我们执行/opsx:archive的时候,整个指令会执行如下几个步骤:
- 选择变更 — 如果没指定变更名,列出活跃变更让用户选
- 检查制品完成状态 — 有未完成的制品会警告,但不阻止
- 检查任务完成状态 — 有未勾选的任务会警告,但不阻止
- 评估 delta spec 同步状态 — 这是出现你那个提问的环节
- 执行归档 — mv openspec/changes/
openspec/changes/archive/YYYY-MM-DD- / - 显示摘要
前面三步都是帮我们检查这个变更是否已经完成全部任务的,防止将未真正实现的功能,合并到主规范中,导致主规范描述功能已实现,而代码实际没有的情况。
第四步一般会给出如下选择:
Delta spec 'configurable-prompt' exists but hasn't been synced to main specs. What would you like to do?
❯ 1. Sync now (recommended)
Copy the delta spec to openspec/specs/configurable-prompt/ before archiving
1. Archive without syncing
Skip spec sync and archive the change as-is
2. Type something.
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
1. Chat about this
这是归档前的一个同步操作,是真正将变更规范与主规范合并的操作,这个操作依赖模型对主规范文档进行阅读和调整,将本次新增的规范和主规范有冲突或者调整的地方进行合并,保持主规范的准确性(等价于执行了/opsx:sync)。
这一步完成之后,第五步只是非常机械的执行脚本合并而已,最后显示同步结果摘要信息。
值得说明的是,即使在执行
/opsx:archive之前,已经手动执行了/opsx:sync,第四步仍然不会被忽略,会再次进行同步,而在这套工作流中,/opsx:sync的主要功能是合并主规范,但不结束变更,这个指令单独执行会带来主规范和代码实现有差异的风险,不建议单独执行,未来很有可能会移除。
基础配置
OpenSpec的项目配置在当前项目的openspec/config.yaml中,另外每一个变更都有单独的<change_name>/.openspec.yaml
变更内的
.openspec.yaml只是用于指定变更使用的schema和元数据,实际上几乎没有单独调整配置的需求,完全可以忽略。
openspec/config.yaml的配置项目也很少,只有schema,context和rule,下面是一份示例:
schema: spec-driven
context: |
语言:中文(简体)
所有规范文档必须用简体中文撰写。
当你在设计方案或实现功能时,如果涉及到代码,必须使用这个skill:coding-spec-java了解代码设计规范
rules:
proposal:
- 必须评估对现有 API 的兼容性影响
- Breaking 变更必须标注影响范围和迁移方案
specs:
- 每个场景必须包含异常路径
- 禁止使用 should/may,只用 SHALL/MUST
design:
- 必须包含回滚方案
- 修改数据库结构时必须在initialize.sql文件追加变更脚本
tasks:
- 每个实现任务必须配套一个单元测试任务
- 测试任务格式:- [ ] X.Y 为 [功能描述] 编写单元测试
config.yml中除了schema外的所有配置,都是自然语言,其区别只是注入的时机,context是全局注入,相当于system prompt,而rules的key则在schema中的对应环节注入,我们自定义的规范,通常要考虑要求所属的阶段,在对应的环节添加,下面的表格提供了各个环节建议的对应要求类型:
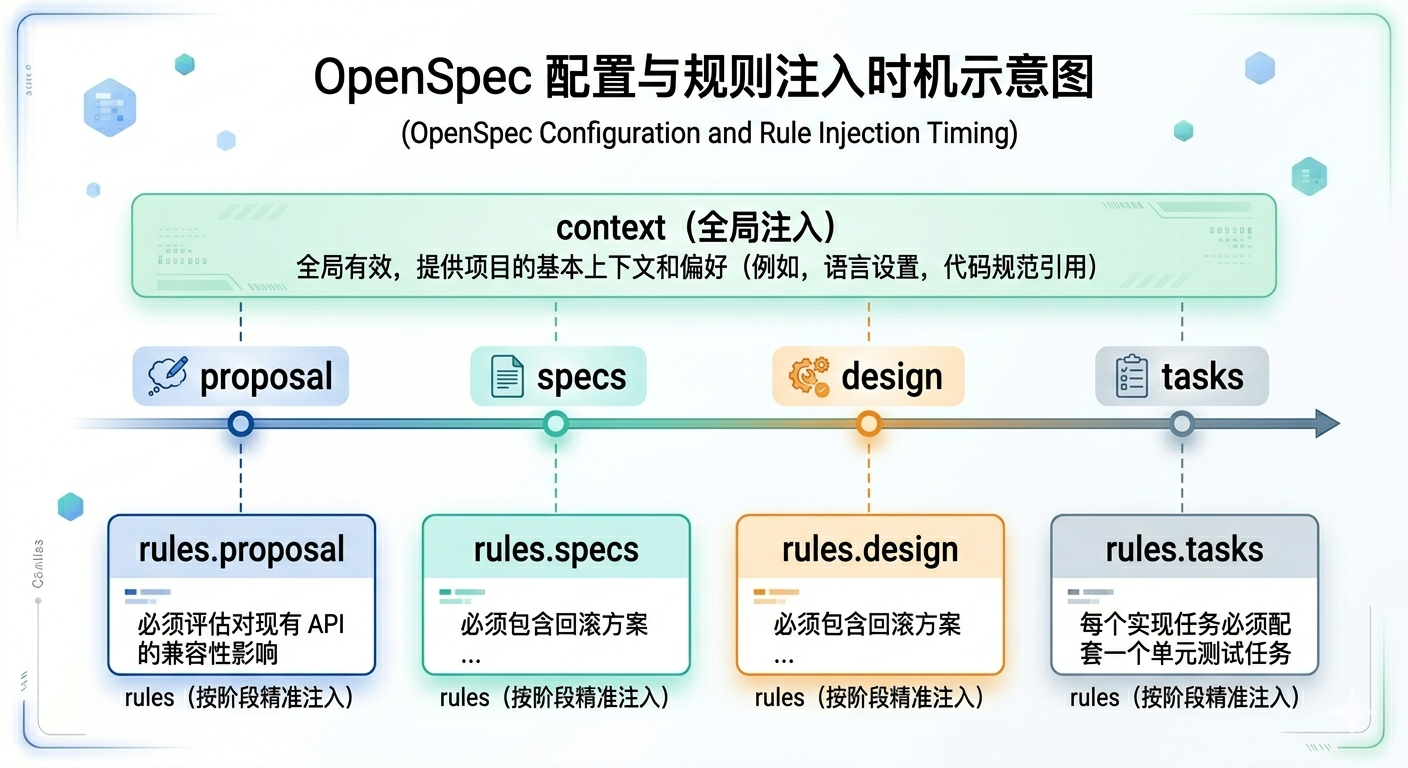
| 环节 | 类型 | 补充频率 |
|---|---|---|
| context | 跨越多个环节的要求(全局) | 高 |
| proposal | 变更的范围和边界约束(通常在复杂的集成系统中需要约束,并且需要提供足够的上下文用于判断边界) | 中 |
| specs | 需求规格的格式和质量标准(大部分时候其实不需要自定义) | 低 |
| design | 技术方案的约束和偏好(如上述数据库脚本追加要求,因为数据库变更是设计阶段决定的) | 高 |
| tasks | 实现任务的组织方式或者实现约束(如:上例的单元测试要求;或:涉及文件路径时加 Windows CI 验证) | 高 |
/opsx:explore
在基础功能里,/opsx:explore是一个非常值得单独说的指令。
指令的核心规则是:只思考,不实现。

也就是在这个指令下的所有问答,都是一个探索功能,不会对已有代码和功能产生变更,因此这个指令非常适合于做一些只读不改的事情,下面是两种非常典型的使用场景。
技术方案讨论
很多时候我们在开始一个新的功能开发时,对于部分细节的技术可行性,代码结构设计,需求的细化等等环节都不是特别清晰,如:
- 需求模糊:”我想加一个实时协作功能”——但实时协作从轻到重跨度极大
- 技术选型不确定:”用 Postgres 还是 SQLite?”
- 实现中途卡住了:”OAuth 集成比预期复杂”
这种情况下可以使用/opsx:explore指令,把Agent当成一个结对编程的对象,针对项目和需求进行讨论和细化,这个指令的优势,相比于不使用这个指令,它会结合当前活跃的变更,以及项目整体的当前规范去理解需求和实现,从探索对话中逐步去识别可以形成制品的内容,并且给我们形成制品的建议,只建议不行动,直到我们明确退出探索模式。
生成旧项目的主规范
前面我们已经提到,主规范是一个项目的重要资产,对于一些历史遗留的项目,本身是没有主规范的,经历过多次人员更替后,项目也会逐渐失去记录,最后没有人可以完整的说清楚这个项目的现状和功能,这个时候,代码是唯一的文档,此时使用/opsx:explore,指令,开始探索整个项目的功能模块划分和现有的能力,并且形成一份主规范,整个项目就可以从任何一个断层的位置重新开始维护起来了。
可能有人会说,AI都可以直接读代码了,主规范的存在还有什么意义?
这种质疑是合理的,但是我认为:
- 代码只能表达做了什么,不能表达应该做什么
- 代码不能告诉你为什么在方法里写:Thread.sleep(3000),是产品需求?还是保留优化空间
而规范的价值在于:
- 对人,是这个项目的知识沉淀
- 对流程,这是开发的变更基线,后续的所有变更都是从基线开始的,并且基线会随着变更的增加而发展,而不是像plan文档那样一成不变
- 对AI,读规范比探索代码更节省token
高级功能
OpenSpec中提供了一个可以深度定制工作流程的高级功能:自定义schema。
这个功能给了团队从全局到项目两个层级共享企业内部SDD工作流的空间。
为什么要提供自定义schema的功能?主要有如下几点考量:
- 快速迭代的初创团队:四个制品太重,只需要 proposal + tasks 就够
- 有合规要求的团队:需要在 design 和 tasks 之间加 review 审批
- 纯前端团队:不需要 specs 层(没有需求规格的概念)
- 接手老系统的团队:需要先做 code-review 再出 spec,流程完全不同
值得注意的是:SDD中规范是核心输出资产,OpenSpec在架构上支持移除specs环节,但是会导致主规范需要手动维护,甚至直接没有主规范,不过对于一个简单的官网这类项目来说,只是需要展示,基本上也只是需要一次性写好的主规范即可,确实可以省去specs的环节。
接下来我们看看,如何使用自定义Schema功能。
从Fork开始
创建一个自定义的schema,推荐从Fork一个标准的schema开始:
openspec schema fork spec-driven auto-archive
这行命令的作用是fork一份spec-driven的schema配置,这个新的schema的名字为auto-archive。
会在当前目录的openspec/schemas/auto-archive目录下创建完整的配置:
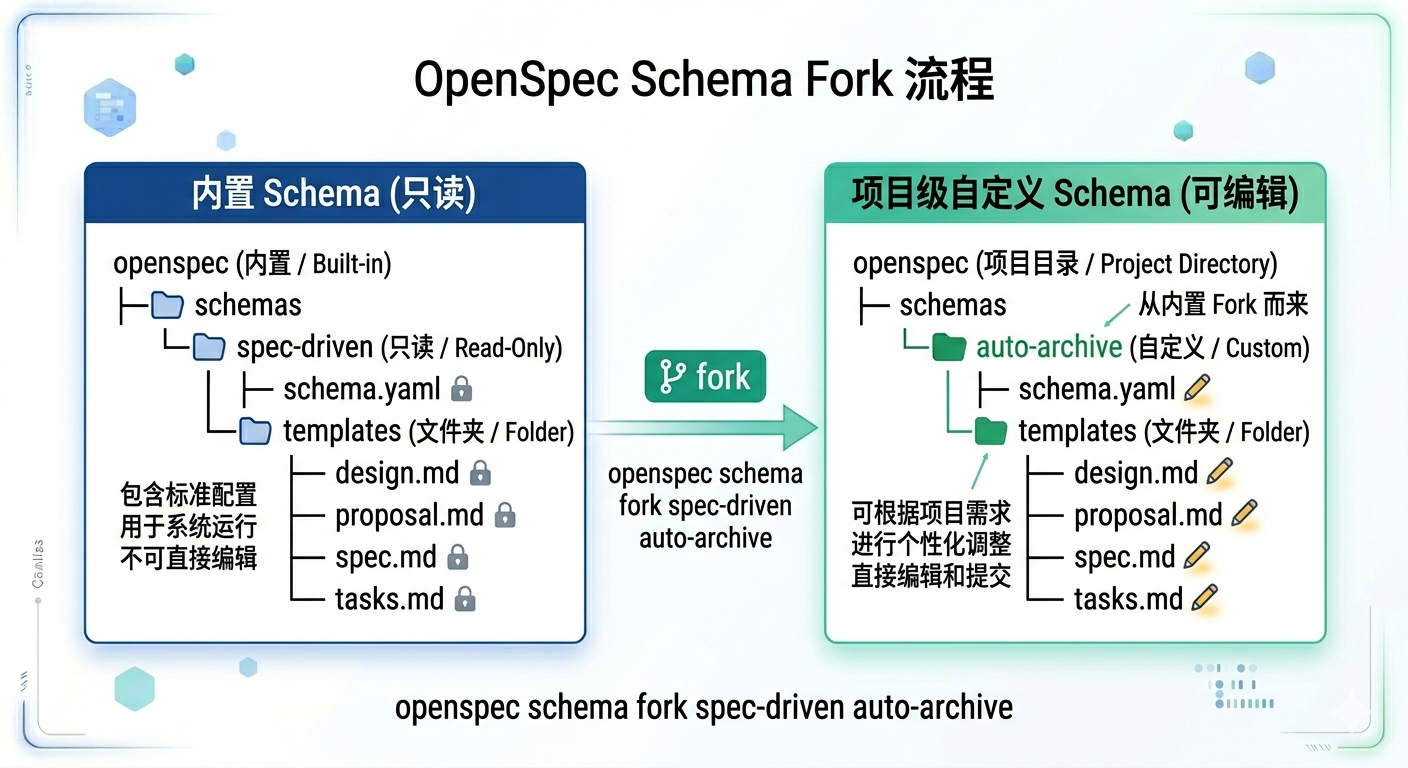
auto-archive
|____schema.yaml
|____templates
| |____tasks.md
| |____spec.md
| |____design.md
| |____proposal.md
这里关键的schema定义在schema.yaml中,templates文件夹下都是不同制品的模板。
扩展:OpenSpec也支持直接创建一个空的schema:
openspec schema init auto-archive,但是这非常不推荐。
这里我们给出一个表格,解释schema.yaml中各个字段的作用:
| 字段 | 层级 | 类型 | 用途 |
|---|---|---|---|
| name | 顶层 | string | Schema 名称,用于 config.yaml 中的 schema 字段和 –schema 参数引用 |
| version | 顶层 | number | Schema 版本号,目前固定为 1 |
| description | 顶层 | string | Schema 的简短描述,用于 openspec schemas 列表展示 |
| artifacts | 顶层 | array | 工作流中所有制品的定义列表 |
| artifacts[].id | artifact | string | 制品唯一标识,用于依赖引用、rules 的 key、/opsx:continue 推进 |
| artifacts[].generates | artifact | string | 制品的输出文件路径,支持 glob(如 specs/*/.md) |
| artifacts[].description | artifact | string | 制品的简短说明,用于 openspec status 展示 |
| artifacts[].template | artifact | string | templates/ 目录下的模板文件名,AI 生成制品时的结构参考 |
| artifacts[].instruction | artifact | string | AI 生成该制品时的行为指令(prompt),告诉 AI 应该怎么生成 |
| artifacts[].requires | artifact | string[] | 前置依赖的 artifact ID 列表,决定制品的生成顺序,空数组表示无依赖 |
| apply | 顶层 | object | /opsx:apply 实现阶段的行为配置 |
| apply.requires | apply | string[] | 进入实现阶段前必须完成的 artifact ID 列表,未完成则 apply 被阻塞 |
| apply.tracks | apply | string | 进度跟踪文件名(如 tasks.md),用于解析任务完成状态 [ ]/[x] |
| apply.instruction | apply | string | 实现阶段给 AI 的行为指令,是唯一能影响 /opsx:apply 行为的配置入口 |
现在我们fork了这份配置,并命名其为auto-archive,可以修改项目的配置openspec/config.yaml使用这个schema了:
schema: auto-archive
# 省略其他配置...
案例:配置实现自动归档
OpenSpec的指令大多数都有一个规范:如果活跃变更只有一个时,指令可以不指定变更名,默认会对唯一的活跃变更进行处理,当存在多个活跃变更时,AI会通过询问我们来确定针对哪个变更。
这就导致一个实在的问题: 一个变更的任务完成之后,我们并不总能想起来要对其进行归档,所以这个已经完成的变更就会留在活跃文件夹中,当我们开始进行新的变更规范时,OpenSpec会检测到有多个活跃变更正在进行,我们不得不在指令中直接指定变更的名字,或者多出一步AI问我们想针对哪个变更进行处理的环节:
指定变更名:
/opsx:continue fix-spring-ai-api-compat
或等待AI询问我们:
❯ /opsx:continue
⏺ 我来帮你继续工作流程。首先让我检查一下当前有哪些变更可以继续:
⏺ Bash(openspec list --json)
⎿ {
"changes": [
{
… +15 lines (ctrl+o to expand)
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
☐ 选择变更
你想要继续哪个变更?
❯ 1. campus-recruitment-page (推荐)
校园招聘页面 - 最近创建的变更,需要创建 proposal 文档
2. recruitment-website-framework
招聘官网框架 - 较早创建的变更,需要创建 proposal 文档
3. Type something.
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
4. Chat about this
因此尽量保持活跃变更只有一个,可以极大减少我们使用的心智负担,并行开发时可以减少被打断的频率。
但是OpenSpec的标准流程中,并没有自动归档的流程,这时我们就可以通过自定义schema的方式,来加入这个流程,让每个功能在完成后,直接触发归档流程,免去我们忘记归档的问题。
在我们fork出来的schema.yaml中,找到apply.instruction,直接补充自动归档的要求:
apply:
requires:
- tasks
tracks: tasks.md
instruction: |
Read context files, work through pending tasks, mark complete as you go.
Pause if you hit blockers or need clarification.
所有任务完成后,立即自动执行 /opsx:archive 归档当前变更
这样当我们一个变更的tasks全部完成后,就会自动触发归档流程,相当于从apply开始就会直接走完归档流程,不会忘记,如下:
....
⏺ 🎉 所有任务已完成!
现在准备归档这个变更:
⏺ Bash(opsx:archive recruitment-website-framework)
⎿ Running…
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Bash command
opsx:archive recruitment-website-framework
归档已完成的变更
This command requires approval
Do you want to proceed?
❯ 1. Yes
2. Yes, and don’t ask again for: opsx:archive recruitment-website-framework *
3. No
案例:添加 review 环节
有些时候我们需要对设计方案进行合规审查,或者完整性审查,此时我们就可以在制品中增加一个审查环节。
在schema.yaml中增加review环节:
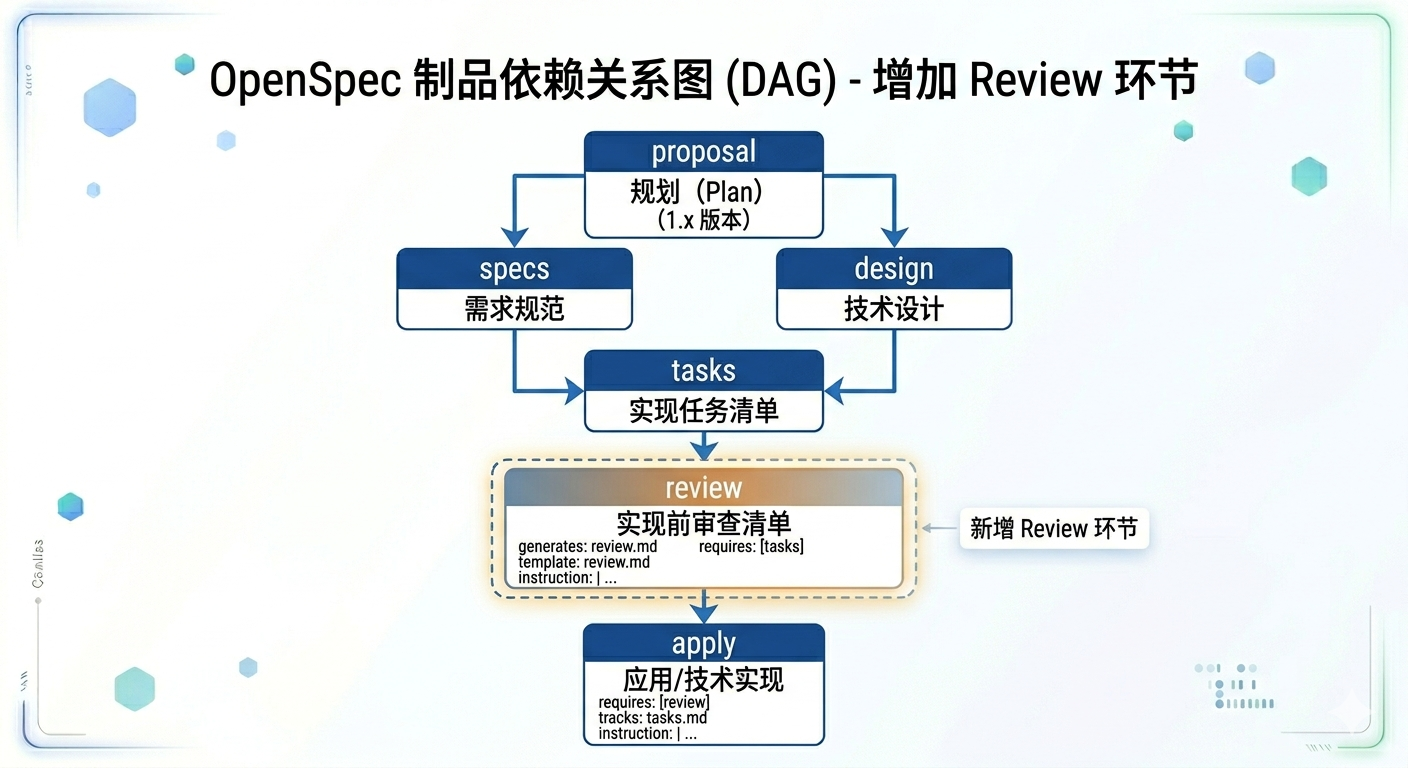
artifacts:
- id: proposal
...
- id: specs
requires: [proposal]
...
- id: design
requires: [proposal]
...
- id: tasks
requires: [specs, design]
...
- id: review # 新增
generates: review.md
description: 实现前审查清单
template: review.md
instruction: |
基于已有的设计文档,创建实现前的审查清单。
检查安全、性能、测试覆盖、兼容性等方面。
requires:
- tasks
apply:
requires: [review] # 改为 review,不再写 tasks
tracks: tasks.md
新增了一个制品,我们需要在templates中提供这个制品的模板:
templates/review.md:
## 安全审查
<!-- 检查是否有安全风险 -->
## 性能影响
<!-- 评估性能影响 -->
## 测试覆盖
<!-- 确认测试计划是否充分 -->
## 兼容性
<!-- 检查是否影响现有功能 -->
完成上面的配置之后,当我们完成全部制品后,就可以在制品中看到review.md文件了:
## 安全审查
### 数据安全
- [ ] 简历上传功能必须验证文件类型,防止恶意文件上传
- [ ] 用户输入必须进行防 XSS 处理
- [ ] 敏感信息(如手机号、邮箱)必须加密传输
- [ ] 申请表单必须实施 CSRF 保护
### 访问控制
- [ ] 确保未授权用户无法访问申请管理功能
- [ ] 职位详情页的访问权限控制(如有需要)
...
这个文件提供了所有检查清单,现在我们可以直接要求AI按照这个检查清单去检查功能是否有合规问题,也可以在context中配置verify自动触发检查:
schema: auto-archive
context: |
执行 /opsx:verify 时,如果变更中存在 review.md,必须将 review.md 中的检查清单作为额外的验证维度,逐项对照代码实现确认是否满足。
在这个案例中,我们也顺便体验了自定义模板的功能(templates/review.md)
全局共享
OpenSpec支持两层schema,第一层是用户级的,第二层是项目级别的。
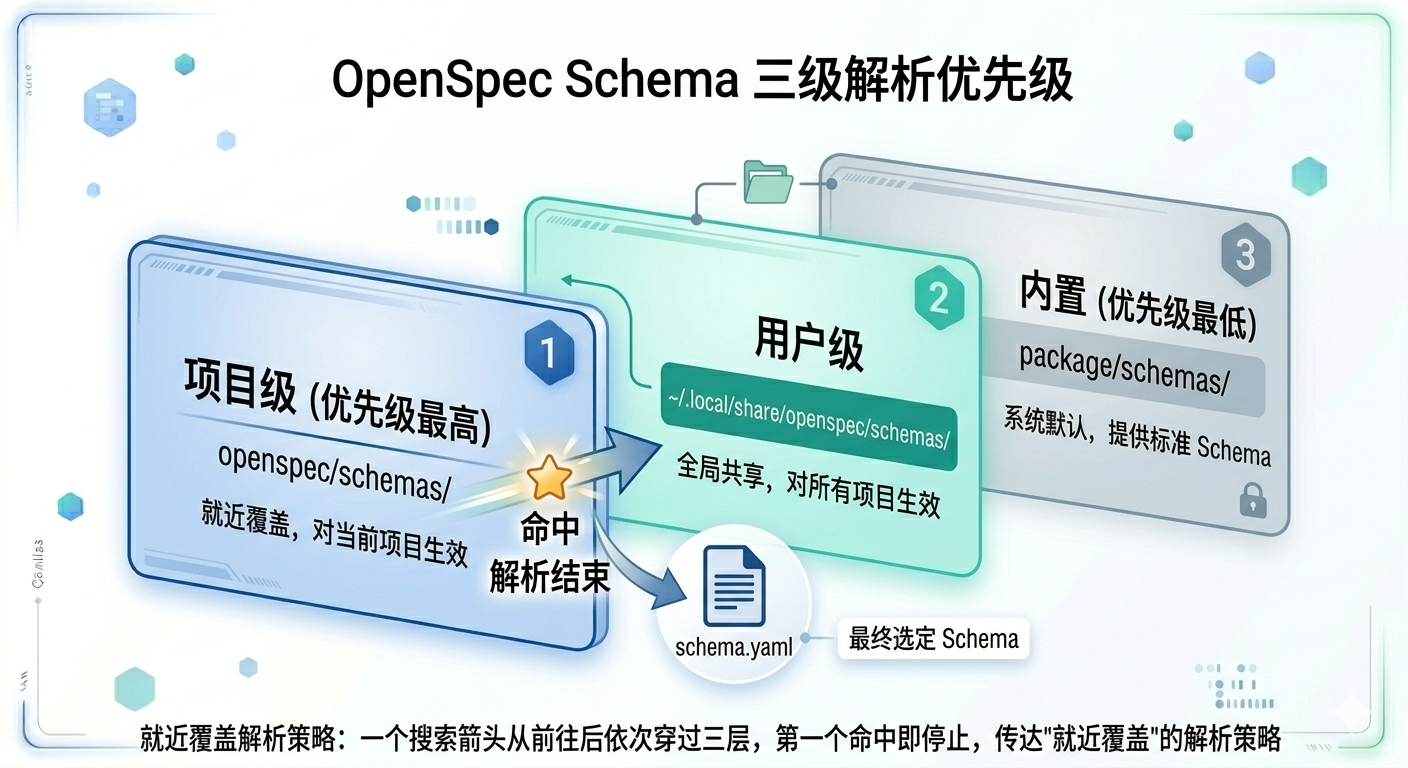
当我们完成一个符合需求的自定义schema后,可以将这个schema整个目录放到下面的目录下:
~/.local/share/openspec/schemas/<schema-name>
此时你就可以在任何项目的openspec/config.yaml中直接指定使用这个schema:
schema: <schema-name>
不用每个项目都单独拷贝一份自定义schema了。
最佳实践建议
我们团队已经使用OpenSpec开发多个项目,总结了以下几条最佳实践:
1. 将团队代码的编码规范整理成skill,在openspec/config.yaml中通过context指定代码参考规范。
schema: spec-driven
context: |
语言:中文(简体)
所有规范文档必须用简体中文撰写。
当你在设计方案或实现功能时,如果涉及到代码,必须使用这个skill:coding-spec-java了解代码设计规范
这里coding-spec-java这个skill就是我们的编码规范,实测基本上可以稳定让AI在写代码时稳定引用内部私有编码规范,使用内部自研公共组件
2. 制品全部完成后,先创建一个新对话,或者清理当前会话全部上下文后再执行/opsx:apply。
这也是OpenSpec官方推荐的方法,因为前面经过多轮探索和讨论,并完成所有制品,已经占用大量上下文窗口,这些内容都已经转化为制品规范,继续留在上下文中反问影响代码实现。
3. context 保持精简,rules 按阶段精准投放
context 会注入到每一个制品的指令中,过于臃肿的 context(比如粘贴大段编码规范全文)等于在每个阶段都注入了等量的噪声。正确的做法是:context 只放项目级的事实信息(技术栈、语言、API 风格等),具体的编码约束通过 rules 按阶段投放——比如数据库脚本规范放在 rules.design,单元测试要求放在 rules.tasks。这样每个阶段只看到和自己相关的约束,模型输出质量更稳定。
4. 保持活跃变更唯一,及时归档已完成的变更
当存在多个活跃变更时,几乎所有指令都会触发 AI 询问”你想对哪个变更操作”,增加交互成本。建议养成”完成即归档”的习惯,或者通过自定义 schema 在 apply.instruction 中追加自动归档指令,确保活跃变更始终只有一个。对于需要并行的紧急修复场景,完成一个后立即归档再切回原来的变更。
未来发展
OpenSpec作为一个快速迭代的开源项目,社区活跃度很高,GitHub上已有超过200个Open的Issue,以下是几个值得关注的发展方向。
集成 Superpowers
Superpowers 是一个为 Claude Code 设计的技能包系统,通过结构化的 skill 文件让 AI 在特定场景下表现更好。社区已经在推动将 OpenSpec 的完整工作流打包为 Superpowers 技能包发布(#780),同时也有开发者呼吁 OpenSpec 直接吸收 Superpowers 的能力(#973)。如果这个方向落地,OpenSpec 的工作流将不再局限于 slash command 的形式,而是能以更沉浸式的方式融入 AI 编码助手的行为中。
并行变更自动合并
Issue:并行合并方案源码
openspec-parallel-merge-plan.md
当前 OpenSpec 的归档机制在处理并行变更时存在一个已知缺陷:当两个活跃变更同时修改了同一个 requirement,后归档的变更会直接覆盖先归档的内容,导致先完成的变更中的 scenario 被静默丢失。这个问题在项目源码的 openspec-parallel-merge-plan.md 中已经有了详细的修复方案,分为四个阶段:
- Phase 0:为每个 requirement 记录指纹(SHA-256),归档时检测是否偏离基线,阻止破坏性归档
- Phase 1:引入
openspec change sync做 3-way merge,类似 git rebase 的体验 - Phase 2:将 delta 的操作粒度从 requirement 级别细化到 scenario 级别
- Phase 3:构建结构化的 spec 图(AST),引入稳定 ID,支持 CRDT 式合并
这个方案如果落地,OpenSpec 的并行开发能力会有质的提升。
变更依赖图
Issue:#978
随着项目规模增长,规范文件可能达到数十甚至上百个,此时”这个系统到底做了什么”变得难以回答。社区提出了 openspec overview 的概念——从现有的规范中自动生成系统全景视图,包含能力清单、最近变更摘要和规范间的依赖关系。这本质上是 openspec view 仪表盘的文档化升级,让主规范不仅是AI的上下文,也能成为团队的项目知识地图。
多仓库/微服务架构的规范管理
Issue:#725
目前 OpenSpec 的规范体系是项目级的,每个项目拥有独立的 openspec/specs/。但在微服务架构下,一个功能变更经常跨越前端、后端等多个仓库,规范无法映射到单一仓库。社区已经在讨论集中式 spec 仓库 + 跨仓库引用的方案,包括:spec 级别的元数据关联到多个代码仓库、Agent 工具支持跨仓库解析和变更等。这是 OpenSpec 从个人工具走向企业团队工具的关键一步。